The Glassbox explore view - attention patterns and next-word probabilities at any point in training
Who this is for
Let me be upfront - if you are an AI researcher, someone who has built their own LLMs, done a bunch of fine tuning, investigated specialized models, this post is not for you. I will not go deep into LLM creation, tuning, etc.
If you are someone who is trying to get a handle on how these things work - who would like a little more insight into what goes on within the “mind” of an LLM, read on.
If you are interested in learning how to do this yourself - how to build some small prototypes and tinker, feel free to reach out to me - this has been an interesting project, and I have learned from it, and I hope others do too.
What this is
About six months ago, I decided I wanted to get a better understanding of how LLMs work. We’ve all heard that they are “next word prediction machines” or things along those lines, and we’ve probably all heard that is complicated to really understand what’s going on inside of them.
So, I set out to build my own LLM from scratch. Not a big fancy LLM (I don’t have nearly the resources for that), but something that could function as a model to help me learn more about how they really work.
I decided to build something small - in the end, just an 11.5 million parameter model with 8 layers and 8 attention heads. Compare this to local LLMs I typically run that are in the 27b to 31b parameter range, with different attention architectures (major differences in how the heads & layers work, and many more of them) - not to mention frontier models, which are estimated to be in the hundreds of billions to trillions of parameters.
The upside of building something small is that I could also build something instrumented. It is true that as a typical LLM responds in a chat, it is looking at the history of the discussion and coming up with what word to pick next (note that some models, like diffusion models - commonly used for image generation - work much differently, but we’re keeping this on the simplistic side). It’s also true that one of the interesting things about working with LLMs is that for any given input (prompt), you will likely get a different output - the models are not deterministic in a sense that most things are in the world of technology.
How it was trained
The model I built is trained on the TinyStories dataset - specifically the GPT-4-generated “V2” version. This is a publicly available set of about 2.7 million short stories (plus a smaller validation set of around 27,000) created by Ronen Eldan and Yuanzhi Li at Microsoft Research. They released it alongside their 2023 paper, TinyStories: How Small Can Language Models Be and Still Speak Coherent English?, and it’s freely available on Hugging Face under the Community Data License Agreement - Sharing (CDLA-Sharing-1.0). Each story is short - a couple of paragraphs at most - and, importantly, they only use vocabulary a 3- or 4-year-old would understand. That small, simple world is exactly what makes it possible for a tiny model to learn to write coherent English at all.
To build the model, I ran it through 50,000 training steps - each step is one small adjustment the model makes as it reads through the stories. On my Nvidia 5090 GPU, this took just a few hours. Every 100 training steps, it paused and the growing model was given 5 different prompts - the responses were captured, along with all the other words/punctuation choices the model considered in its response. This isn’t a chat model - it’s a storyteller. The prompts it was given were:
- Once upon a time
- The boy was very
- She went to the
- The dog and the cat
- He was happy because
And from there, the model completed the tiny story. So that’s 5 results captured every 100 training steps, of which there were 50,000 - so that means 2,500 individual responses were measured and captured.
What you will find is that as the training continues, it starts to “understand” more how to tell a story. If you look after just 100 steps, it’s pure gibberish - the prompt “The boy was very” is answered by “coming net facts, numbersetha careixirts contest string…” - truly a poor attempt at a story. But by training step 50,000, that same prompt returns “clever, so he carefully picked up the rabbit and took it outside.” and so forth. A big difference. The rabbit turns out fine, in case you were wondering.
How it works
A quick reminder before we look inside: this is not a very “smart” LLM. It is small and, when fully trained, can keep track of a couple sentences - little stories. It can’t tell you the capital of Greece, Nebraska, call any tools, do anything remotely agentic, or remember your name (or really anything, for that matter). It was built simply as a tool to help me understand what really goes on inside an LLM when it is formulating a response to a prompt.
One interesting thing: the model doesn’t always pick the word it considers most likely - it will often choose a lower-probability one on purpose.
The model itself is instrumented so that for every word it picks in response to a prompt, it shows you the top 10 words (or punctuation) that it considered, along with the probability of each choice. That tendency to pick a lower-probability option comes from a certain randomness the model is guided towards - this is referred to as “temperature”. In the consumer chat apps for the big closed models, this is set for you and the default isn’t disclosed. In an open-weights model, especially a local one, this is something very tunable. Give it a higher temperature, and it will be more random. Set the temperature low - towards 0 - and it will actually become more deterministic. For many uses, models are typically set somewhere around 0.7 (there are other settings that influence this as well - top_p, top_k, but again, we’re keeping this at a fairly high level). Suffice to say, that the more randomness introduced, the more likely it is that it will pick something of a lower probability, perhaps something surprising.
When you multiply the randomness over multiple layers - how it considers the previous parts of the conversation - including words it has already generated itself - you begin to understand why the output can vary so much. When you apply the same math to larger and more complex models, then you begin to understand the difficulty in mapping out exactly what is happening. This is what makes the small, instrumented model such a valuable learning tool.
The website
If you go to https://glassbox.brianhengen.us/ you will see an overview of the model and how it progressed through its training.
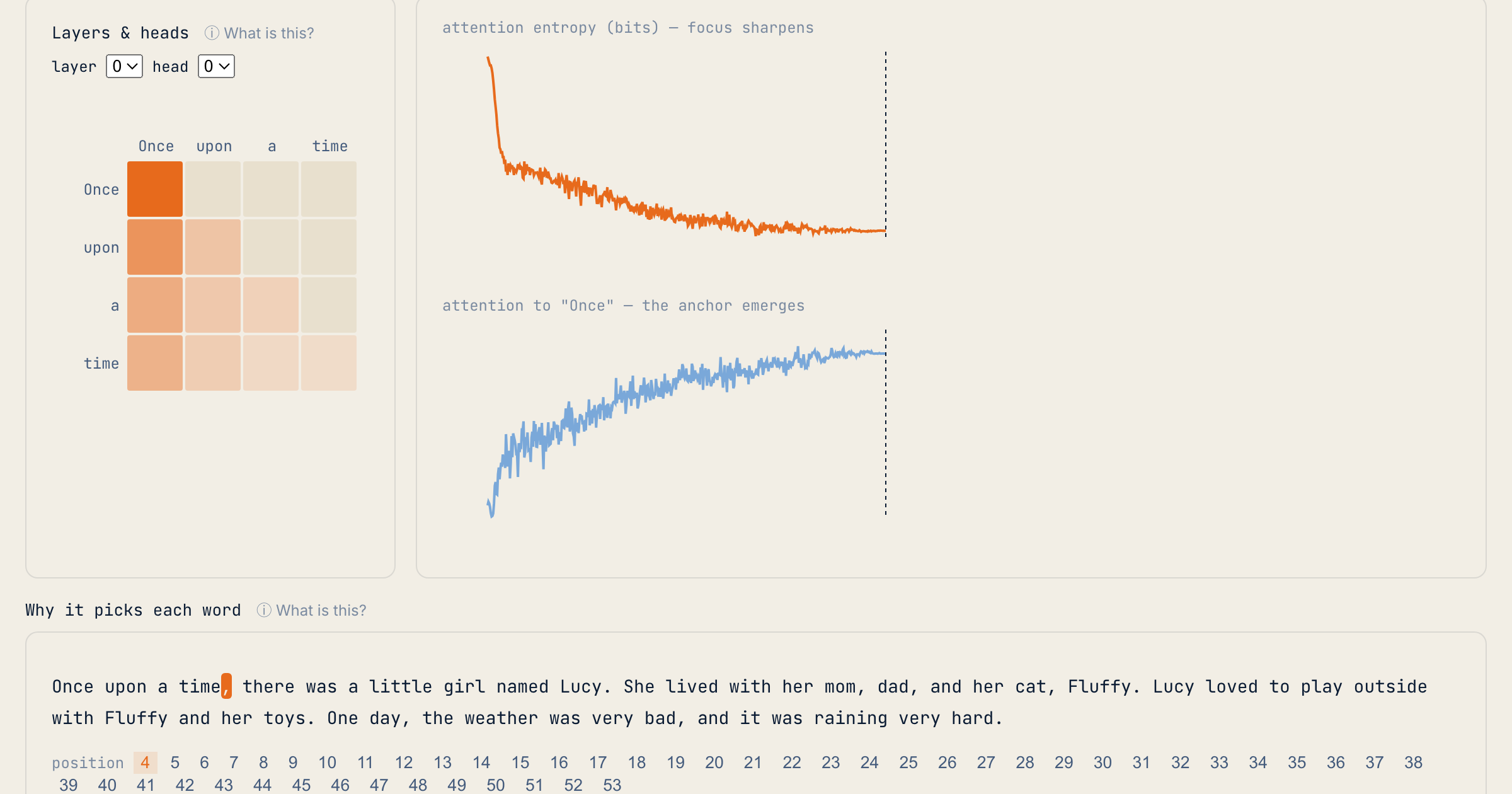
If you are interested in more detail, click the “Explore it yourself” link at the bottom of the page, or just go to https://glassbox.brianhengen.us/explore for the interactive view. In there, you will be able to select a training step (in increments of 100), see how the attention mechanism changes throughout training (the earlier words to focus on when choosing the next one), and at the bottom of the page, you will see the output for the prompt and training step picked at the top of the page. Want to see what other words were considered - just click on one and it will show you. Want to know more, just click on one of the “What is this?” links, and it will expand to show more details.
What you’re seeing on the site
I built this at the beginning of 2026 and I shared it with a few folks who found it interesting, so I decided to make it broadly available.
When you go to the website (https://glassbox.brianhengen.us/) you are really looking at static, captured data, not the live LLM. The live LLM runs on my server. To build the interactive reporting for the website, I did a fresh build and training of the LLM and captured the output data (the prompts, the responses, alternate choices, metrics, etc.), staged it, and connected it to the website.
Thank you
I hope you find this as interesting and informative as I did - it was a fun project. The technology is amazing - and when you really think about what the larger models do, how much they process, and how quickly they are able to respond, it’s beyond impressive. As Arthur C. Clarke said, “Any sufficiently advanced technology is indistinguishable from magic.” My goal here was to demystify this a bit, so not magic, but it’s a long way from the old Atari 400 I learned to program on…
About the Author
Brian Hengen is a Vice President at Oracle, leading technical sales engineering teams. The views and opinions expressed in this blog are his own and do not necessarily reflect those of Oracle.